
Red Neuronal Convolucional: Funcionamiento y Aprendizaje Automático
En el campo del aprendizaje automático y la inteligencia artificial, las Redes Neuronales Convolucionales (RNC) han sido una de las mayores innovaciones de los últimos años. Estas redes están basadas en el funcionamiento del cerebro humano y son capaces de aprender y reconocer patrones en datos visuales, como imágenes y vídeos. Su aplicación en diversas áreas, como el reconocimiento de imágenes, la visión por computadora y la conducción autónoma, ha revolucionado la manera en que las máquinas pueden procesar información y tomar decisiones.
Exploraremos en detalle el funcionamiento de las Redes Neuronales Convolucionales, con el objetivo de entender cómo son capaces de aprender y reconocer patrones visuales. Veremos cómo estas redes utilizan filtros y capas convolucionales para extraer características de las imágenes, y cómo las capas de pooling reducen la dimensionalidad de los datos. Además, examinaremos cómo las Redes Neuronales Convolucionales son entrenadas utilizando algoritmos de retropropagación del error y cómo se puede mejorar su rendimiento mediante técnicas como la regularización y el uso de conjuntos de datos de entrenamiento más grandes.
- Qué es una red neuronal convolucional y cómo funciona
- Cuáles son las aplicaciones más comunes de las redes neuronales convolucionales
- Cómo se entrena una red neuronal convolucional para reconocer patrones
- Cuál es la diferencia entre una red neuronal convolucional y una red neuronal tradicional
- Qué tipo de datos se pueden utilizar para entrenar una red neuronal convolucional
- Cuáles son las limitaciones o desafíos de las redes neuronales convolucionales
- Existen bibliotecas o frameworks populares para trabajar con redes neuronales convolucionales
- Cuáles son algunos ejemplos de casos de éxito en el uso de redes neuronales convolucionales
- Cómo se seleccionan los hiperparámetros adecuados para una red neuronal convolucional
- Cuáles son las tendencias actuales en el campo de las redes neuronales convolucionales
- Existen diferencias en el funcionamiento de las redes neuronales convolucionales según el problema a resolver
- Es posible combinar una red neuronal convolucional con otro tipo de modelo de aprendizaje automático
- Cuál es el papel de la transferencia de aprendizaje en las redes neuronales convolucionales
- Existen retos éticos o de privacidad asociados al uso de redes neuronales convolucionales
- Qué se puede hacer para mejorar el rendimiento y la precisión de una red neuronal convolucional
- Preguntas frecuentes (FAQ)
- 1. ¿Qué es una red neuronal convolucional (CNN)?
- 2. ¿Cómo funciona una red neuronal convolucional?
- 3. ¿Cuál es la ventaja de utilizar una red neuronal convolucional en el procesamiento de imágenes?
- 4. ¿Cuál es el proceso de entrenamiento de una red neuronal convolucional?
- 5. ¿En qué aplicaciones se utiliza una red neuronal convolucional?
Qué es una red neuronal convolucional y cómo funciona
Una red neuronal convolucional (CNN) es un tipo de modelo de aprendizaje automático inspirado en el funcionamiento del cerebro humano. Está diseñada específicamente para procesar datos con una estructura en forma de cuadrícula, como imágenes o secuencias de audio.
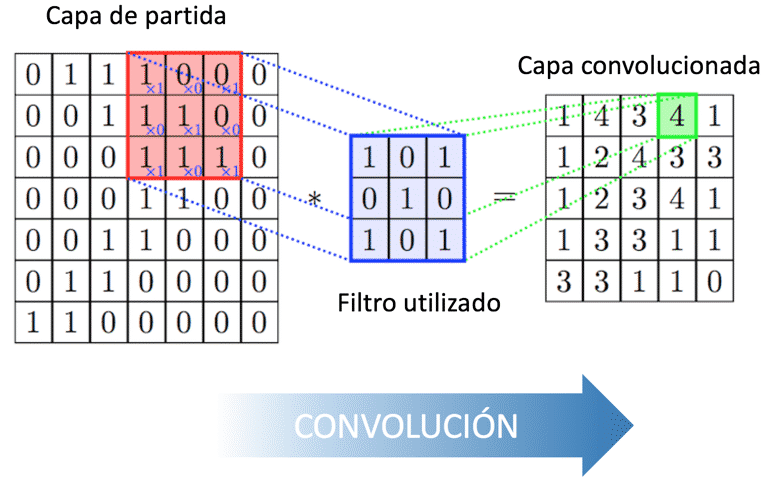
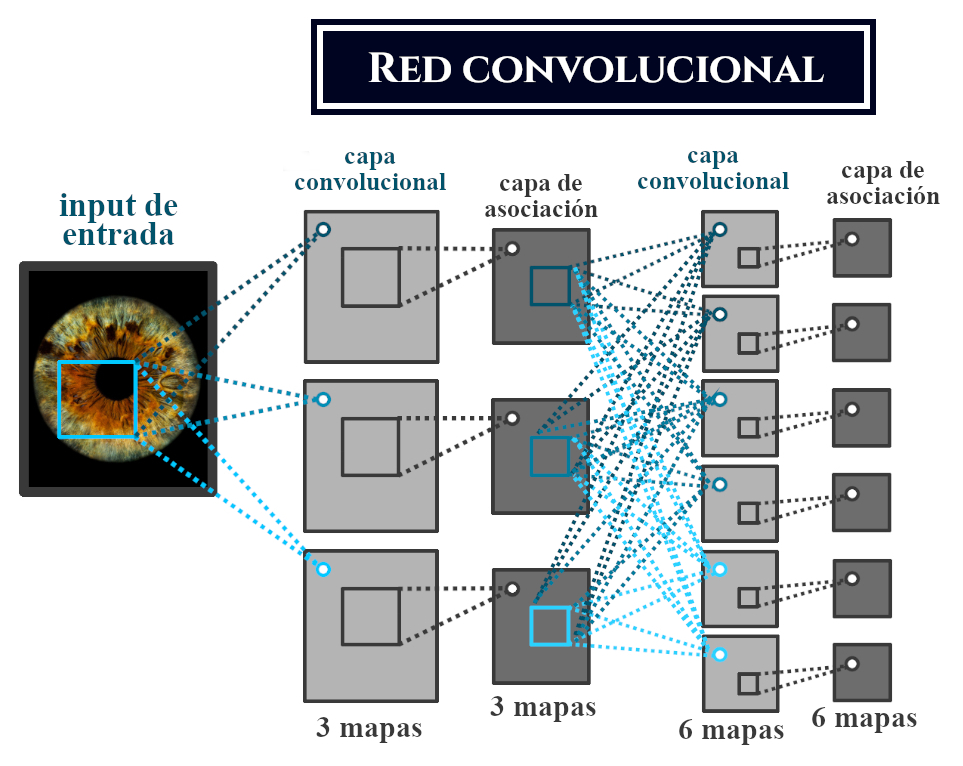
El funcionamiento de una CNN se basa en capas de neuronas artificiales interconectadas. Cada capa está compuesta por un conjunto de filtros o "kernels" que se aplican de manera convolucional a la entrada. Estos filtros extraen características relevantes de los datos, como bordes, texturas o patrones visuales.
Después de la convolución, se aplica una operación de "pooling" que reduce la dimensionalidad de los datos. Esto ayuda a conservar las características más importantes mientras se reduce el número de parámetros y se mejora la eficiencia del modelo.
A continuación, las características extraídas se conectan a una o varias capas totalmente conectadas, también llamadas "capas densas", donde se realiza la clasificación o regresión final.
Una red neuronal convolucional es capaz de aprender automáticamente las características más relevantes de los datos de entrada, permitiendo realizar tareas como clasificación de imágenes, detección de objetos o reconocimiento de voz con gran precisión y eficiencia.
Cuáles son las aplicaciones más comunes de las redes neuronales convolucionales
Las redes neuronales convolucionales (CNN, por sus siglas en inglés) son una técnica avanzada de aprendizaje automático que ha revolucionado muchas áreas. Su principal fortaleza radica en su capacidad para procesar imágenes y extraer características relevantes para la clasificación y reconocimiento de objetos.
Una de las aplicaciones más comunes de las CNN es en la visión por computadora. Estas redes han demostrado ser altamente efectivas en tareas de reconocimiento facial, detección de objetos, segmentación de imágenes y clasificación de imágenes médicas.
Otra área en la que las CNN han tenido un gran impacto es en la conducción autónoma. Al utilizar redes neuronales convolucionales, los vehículos autónomos pueden procesar rápidamente la información visual de los sensores y tomar decisiones en tiempo real para una conducción segura y eficiente.
Además, las redes neuronales convolucionales también se utilizan en la industria del entretenimiento, particularmente en el campo de la realidad virtual y aumentada. Estas redes pueden analizar y procesar imágenes en tiempo real para brindar experiencias inmersivas y realistas a los usuarios.
Otras aplicaciones notables de las CNN incluyen el análisis de videos para la detección de objetos en movimiento, el reconocimiento óptico de caracteres (OCR), el análisis de sentimientos en redes sociales y la mejora de la calidad de imágenes y videos.
Las redes neuronales convolucionales tienen una amplia gama de aplicaciones en diversas industrias y campos, como la visión por computadora, la conducción autónoma, la realidad virtual y aumentada, el análisis de videos, el reconocimiento óptico de caracteres y el análisis de sentimientos en redes sociales. Su capacidad para procesar imágenes y extraer características relevantes las convierte en una herramienta indispensable para el aprendizaje automático.
Cómo se entrena una red neuronal convolucional para reconocer patrones
Entrenar una red neuronal convolucional (CNN) para reconocer patrones es un proceso complejo pero fascinante. Primero, se debe alimentar a la red con un conjunto de datos de entrenamiento etiquetados, que consiste en imágenes y las correspondientes etiquetas de las clases a las que pertenecen. La red utiliza estos datos para aprender a reconocer características distintivas en las imágenes.
La primera etapa del entrenamiento implica la convolución. La red aplica una serie de filtros a las imágenes de entrada para detectar características como bordes, esquinas y texturas. Estos filtros se aplican a diferentes partes de la imagen y generan mapas de características.
Luego, se aplica una función de activación, como la función ReLU, a los mapas de características para introducir no linealidades en el proceso. Esto ayuda a la red a aprender patrones más complejos y abstractos.
A continuación, se aplica un submuestreo o pooling para reducir la dimensionalidad de los mapas de características y preservar las características más importantes. Esto ayuda a mejorar la eficiencia computacional y evitar el sobreajuste.
Después de la etapa de convolución y submuestreo, se utiliza una o varias capas totalmente conectadas para clasificar las características aprendidas en las diferentes clases. Estas capas toman los mapas de características y los aplastan en un vector, que luego se alimenta a una o varias capas de salida con funciones de activación adecuadas, como la función de activación softmax para la clasificación.
Finalmente, el proceso de entrenamiento implica el cálculo de una función de pérdida, que compara la salida predicha por la red con las etiquetas verdaderas y mide la discrepancia entre ellas. La red utiliza esta función de pérdida para ajustar sus pesos y biases mediante algoritmos de optimización, como la retropropagación del error, con el objetivo de minimizar la pérdida y mejorar su rendimiento.
Este proceso se repite durante múltiples iteraciones, conocidas como épocas, hasta que la red haya aprendido suficientes patrones y sea capaz de realizar clasificaciones precisas en nuevas imágenes de prueba. Es importante destacar que el entrenamiento de una red neuronal convolucional puede llevar mucho tiempo y requiere una gran cantidad de recursos computacionales.
Cuál es la diferencia entre una red neuronal convolucional y una red neuronal tradicional
Las redes neuronales convolucionales (CNN) son un tipo de arquitectura de redes neuronales diseñadas específicamente para procesar datos en forma de matrices, como imágenes. A diferencia de las redes neuronales tradicionales, las CNN utilizan capas convolucionales para extraer características de las imágenes de entrada. Estas capas aplican filtros convolucionales a las imágenes para detectar patrones específicos.
Por otro lado, las redes neuronales tradicionales están compuestas por capas completamente conectadas, en las que cada neurona está conectada a todas las neuronas de la capa anterior y posterior. Esto hace que las redes neuronales tradicionales sean más adecuadas para tareas en las que la estructura espacial de los datos no es relevante, como el procesamiento de texto o la predicción de series temporales.
La principal diferencia entre una red neuronal convolucional y una red neuronal tradicional radica en su capacidad para procesar datos estructurados. Mientras que las CNN son ideales para tareas de visión por computadora y procesamiento de imágenes, las redes neuronales tradicionales son más adecuadas para tareas de procesamiento de lenguaje natural y análisis de datos secuenciales.
Qué tipo de datos se pueden utilizar para entrenar una red neuronal convolucional
Una red neuronal convolucional es un tipo especializado de modelo de aprendizaje automático que ha demostrado ser muy efectivo en la tarea de reconocimiento de patrones en imágenes y videos. Para entrenar una red neuronal convolucional, se requiere un conjunto de datos de entrenamiento. Los datos utilizados para entrenar una red neuronal convolucional son generalmente imágenes, aunque también se pueden utilizar otros tipos de datos como videos o datos de audio.
En el caso de imágenes, se necesita un conjunto de imágenes etiquetadas, es decir, cada imagen debe tener asociada una etiqueta que indique la clase a la que pertenece. Por ejemplo, si estamos entrenando una red neuronal convolucional para reconocer objetos en imágenes, las etiquetas podrían ser "perro", "gato", "coche", etc.
Es importante asegurarse de que el conjunto de datos de entrenamiento sea lo suficientemente grande y representativo de todas las clases que queremos que la red neuronal convolucional sea capaz de reconocer. Además, es recomendable contar con un conjunto de datos de validación y un conjunto de datos de prueba para evaluar el rendimiento del modelo después de entrenarlo.
Cuáles son las limitaciones o desafíos de las redes neuronales convolucionales
Las redes neuronales convolucionales (CNN) son ampliamente utilizadas en el campo del aprendizaje automático debido a su capacidad para procesar y analizar datos de imágenes de manera eficiente. Sin embargo, como cualquier otro enfoque, las CNN también tienen sus limitaciones y desafíos.
1. Requieren una gran cantidad de datos de entrenamiento
Las CNN necesitan una gran cantidad de datos de entrenamiento para poder aprender patrones y características relevantes. Esto puede ser un desafío, especialmente cuando se tienen conjuntos de datos limitados o costosos de obtener.
2. Son computacionalmente intensivas
El entrenamiento de una CNN requiere una gran cantidad de poder de cómputo y tiempo. Esto se debe a la complejidad de los cálculos involucrados en las operaciones convolucionales y de pooling. Además, a medida que aumenta la profundidad y el tamaño de la red, el costo computacional también aumenta.
3. Dificultad para capturar relaciones espaciales de largo alcance
Las CNN están diseñadas para capturar patrones locales en datos de imágenes. Sin embargo, tienen dificultades para capturar relaciones espaciales de largo alcance. Esto se debe a que las operaciones convolucionales están restringidas a un tamaño de ventana definido y no pueden capturar información global en una imagen.
4. Sensibilidad a perturbaciones y distorsiones
Las CNN son susceptibles a variaciones en la posición, rotación, escala y iluminación de objetos en una imagen. Esto puede llevar a una reducción en el rendimiento de la red, ya que las características aprendidas pueden no generalizar bien a nuevas instancias.
5. Interpretabilidad y explicabilidad
Una de las limitaciones más importantes de las CNN es su falta de interpretabilidad y explicabilidad. A diferencia de otros enfoques de aprendizaje automático, las CNN no proporcionan explicaciones claras sobre cómo llegan a sus decisiones. Esto puede ser un desafío cuando se requiere explicar y justificar los resultados del modelo.
En resumen
A pesar de estas limitaciones y desafíos, las redes neuronales convolucionales siguen siendo una herramienta poderosa en el campo del aprendizaje automático, especialmente en tareas de procesamiento de imágenes. Con el avance de la investigación y el desarrollo tecnológico, es probable que muchas de estas limitaciones sean superadas en el futuro, haciendo que las CNN sean aún más efectivas y versátiles.
Existen bibliotecas o frameworks populares para trabajar con redes neuronales convolucionales
Existen diferentes bibliotecas o frameworks populares que facilitan el trabajo con redes neuronales convolucionales. Algunos de los más conocidos y ampliamente utilizados son:
TensorFlow: desarrollado por Google, es una de las opciones más populares y ampliamente utilizadas. Proporciona una amplia gama de herramientas y funcionalidades para el diseño, entrenamiento e implementación de redes neuronales convolucionales.PyTorch: desarrollado por Facebook, es otra opción muy popular. Se destaca por su capacidad de ejecución eficiente en GPU y su flexibilidad en la construcción y entrenamiento de modelos de redes neuronales convolucionales.Keras: se encuentra sobre el framework de TensorFlow y proporciona una interfaz de alto nivel y fácil de usar para la construcción y entrenamiento de redes neuronales convolucionales.Caffe: es una biblioteca popular utilizada principalmente en el ámbito de la visión por computadora. Se caracteriza por su velocidad y eficiencia en la implementación de modelos de redes neuronales convolucionales.
Estas bibliotecas ofrecen una amplia gama de herramientas y funcionalidades que simplifican el proceso de desarrollo y entrenamiento de redes neuronales convolucionales, permitiendo a los usuarios aprovechar al máximo esta poderosa técnica de aprendizaje automático.
Cuáles son algunos ejemplos de casos de éxito en el uso de redes neuronales convolucionales
Las redes neuronales convolucionales (CNN, por sus siglas en inglés) han demostrado ser altamente efectivas en una amplia gama de aplicaciones. Uno de los casos de éxito más destacados es su utilización en el campo de la visión por computadora. Las CNN han permitido avances significativos en tareas como reconocimiento facial, clasificación de imágenes y detección de objetos.
Un ejemplo destacado es la aplicación de las CNN en el campo de la medicina. Estas redes han demostrado ser capaces de diagnosticar enfermedades a partir de imágenes médicas con una precisión incluso mayor que los médicos humanos. Esto ha revolucionado la forma en que se realizan los diagnósticos, permitiendo detectar enfermedades en etapas tempranas y mejorar la eficiencia del sistema de salud.
Otro ejemplo notable es el uso de las redes neuronales convolucionales en la industria automotriz. Estas redes se utilizan en sistemas de visión por computadora para detectar peatones, señales de tránsito y otros objetos relevantes en la conducción autónoma. Gracias a las CNN, los vehículos autónomos pueden tomar decisiones rápidas y precisas, lo que reduce significativamente el riesgo de accidentes y mejora la seguridad vial.
Además, las redes neuronales convolucionales son ampliamente utilizadas en el campo de la seguridad informática. Estas redes son capaces de detectar patrones y anomalías en grandes volúmenes de datos, lo que las hace ideales para la detección de intrusiones y ataques cibernéticos. Esto ha ayudado a proteger sistemas y redes de empresas y organizaciones de todo el mundo.
Los casos de éxito en el uso de las redes neuronales convolucionales son numerosos y abarcan diversos sectores. Estas redes han revolucionado la visión por computadora, la medicina, la industria automotriz y la seguridad informática, entre otros campos. Su capacidad para procesar y analizar grandes cantidades de datos de manera eficiente las convierte en una herramienta invaluable en el aprendizaje automático.
Cómo se seleccionan los hiperparámetros adecuados para una red neuronal convolucional
Seleccionar los hiperparámetros adecuados para una red neuronal convolucional puede marcar la diferencia entre un modelo eficiente y uno ineficaz. Los hiperparámetros son valores numéricos que controlan el comportamiento y rendimiento del modelo, como el número de capas, el tamaño de los filtros y la tasa de aprendizaje.
Para seleccionar los hiperparámetros adecuados, es necesario realizar una búsqueda exhaustiva en el espacio de posibles combinaciones. Una opción es utilizar la validación cruzada para evaluar el rendimiento del modelo en diferentes conjuntos de datos. Esta técnica implica dividir los datos en conjuntos de entrenamiento, validación y prueba, y ajustar los hiperparámetros en función del rendimiento en el conjunto de validación.
Una forma común de seleccionar los hiperparámetros es a través de la búsqueda en cuadrícula, donde se especifica un conjunto de valores para cada hiperparámetro y se entrena el modelo con todas las combinaciones posibles. Sin embargo, esta técnica puede ser costosa computacionalmente y llevar mucho tiempo.
Otra opción es utilizar la optimización bayesiana, que busca encontrar la combinación óptima de hiperparámetros a través de un proceso iterativo de prueba y error. Esta técnica utiliza modelos probabilísticos para modelar la relación entre los hiperparámetros y el rendimiento del modelo, y realiza una búsqueda basada en el resultado de las iteraciones anteriores.
Además, es importante considerar la capacidad computacional disponible al seleccionar los hiperparámetros. Modelos más complejos con muchos filtros y capas pueden requerir una gran cantidad de recursos computacionales, lo que puede limitar la elección de hiperparámetros.
Seleccionar los hiperparámetros adecuados para una red neuronal convolucional implica una combinación de técnicas como la validación cruzada, la búsqueda en cuadrícula y la optimización bayesiana. Es necesario tener en cuenta el rendimiento del modelo en diferentes conjuntos de datos, así como la capacidad computacional disponible. La selección cuidadosa de los hiperparámetros puede mejorar significativamente el rendimiento y la eficiencia del modelo.
Cuáles son las tendencias actuales en el campo de las redes neuronales convolucionales
Las redes neuronales convolucionales (CNN por sus siglas en inglés) son uno de los mayores avances en el campo del aprendizaje automático en los últimos años. Su capacidad para procesar datos de manera eficiente y extraer características significativas los ha convertido en una herramienta poderosa en diversas aplicaciones, como reconocimiento de imágenes, procesamiento de lenguaje natural y análisis de señales.
En la actualidad, hay varias tendencias en desarrollo que están llevando a las redes neuronales convolucionales a un nivel aún más alto. Una de estas tendencias es el uso de arquitecturas más profundas, que permiten una mayor capacidad de aprendizaje y generalización. Esto se logra mediante la adición de capas adicionales en la red, lo que permite que el modelo aprenda patrones más complejos y abstractos en los datos.
Otra tendencia importante es la utilización de técnicas de regularización, como la regularización L1 y L2, que ayudan a evitar el sobreajuste y mejorar la generalización del modelo. Estas técnicas penalizan los pesos de la red que son demasiado grandes, lo que a su vez permite que el modelo se ajuste mejor a nuevos datos.
Además, se están desarrollando nuevas técnicas de inicialización de pesos, como la inicialización de He y la inicialización de avier, que ayudan a evitar el problema del desvanecimiento de gradientes y mejoran la capacidad de convergencia de la red.
Otra tendencia interesante es el uso de arquitecturas más eficientes en términos de cálculo y memoria, como las redes neuronales convolucionales con estructuras de bloque, donde se agrupan varias capas convolucionales en un solo bloque. Esto permite reducir la cantidad de parámetros y acelerar el entrenamiento y la inferencia de la red.
Por último, pero no menos importante, está la tendencia hacia el uso de técnicas de transferencia de aprendizaje, donde los modelos pre-entrenados en grandes conjuntos de datos, como ImageNet, se utilizan como punto de partida para entrenar nuevos modelos en tareas específicas. Esto permite aprovechar el conocimiento adquirido por el modelo pre-entrenado y acelerar significativamente el proceso de entrenamiento.
Las redes neuronales convolucionales están experimentando continuas innovaciones y mejoras que las hacen aún más potentes y versátiles. A medida que se sigan desarrollando estas tendencias, es probable que las CNN continúen impulsando el campo del aprendizaje automático y sigan siendo una herramienta fundamental en diversas aplicaciones.
Existen diferencias en el funcionamiento de las redes neuronales convolucionales según el problema a resolver
Las redes neuronales convolucionales (CNN, por sus siglas en inglés) son un tipo de arquitectura de redes neuronales artificiales que se utilizan comúnmente en problemas de visión por computadora y reconocimiento de patrones. Estas redes se inspiran en la organización del sistema visual de los seres vivos y son especialmente adecuadas para procesar datos con estructura espacial, como imágenes y videos.
El funcionamiento de una CNN se basa en el uso de filtros convolucionales que se aplican a la entrada de datos para detectar características específicas. Estos filtros se deslizan por la imagen, calculando productos escalares entre los pesos del filtro y los píxeles correspondientes en cada posición. De esta manera, la red es capaz de extraer características relevantes a diferentes niveles de abstracción.
El aprendizaje automático de una CNN se basa en el principio de retropropagación del error. Durante la fase de entrenamiento, la red ajusta los pesos de sus filtros convolucionales mediante un proceso iterativo de optimización, minimizando la diferencia entre las salidas predichas y las salidas deseadas. Este proceso se realiza utilizando algoritmos de optimización como el descenso del gradiente estocástico.
Es importante destacar que el funcionamiento de una CNN puede variar según el problema a resolver. En algunos casos, es posible que se requieran capas adicionales de convolución para capturar características más complejas. Además, se pueden utilizar capas de agrupamiento (pooling) para reducir la dimensionalidad de los datos y evitar el sobreajuste.
Las redes neuronales convolucionales son una herramienta poderosa en el campo del aprendizaje automático, especialmente en problemas relacionados con la visión por computadora. Su funcionamiento se basa en el uso de filtros convolucionales que se aplican a la entrada de datos para detectar características relevantes. Sin embargo, es importante tener en cuenta que su funcionamiento puede variar según el problema a resolver, por lo que es necesario ajustar la arquitectura de la red de acuerdo a las características del problema.
Es posible combinar una red neuronal convolucional con otro tipo de modelo de aprendizaje automático
La combinación de una red neuronal convolucional (CNN) con otros modelos de aprendizaje automático es una estrategia cada vez más común en el campo de la inteligencia artificial. Esto se debe a que las CNN son especialmente efectivas en el procesamiento de datos visuales, como imágenes o videos, pero tienen limitaciones cuando se trata de manejar otros tipos de información, como texto o sonido.
Al combinar una CNN con otro modelo de aprendizaje automático, se pueden aprovechar las fortalezas de ambos enfoques para lograr una mejor comprensión de los datos y obtener resultados más precisos. Por ejemplo, se ha demostrado que combinar una CNN con un modelo de lenguaje natural puede mejorar significativamente el rendimiento en la traducción automática o en el reconocimiento de voz.
La forma en que se combinen estos modelos puede variar según el problema específico que se esté abordando. En algunos casos, se puede utilizar la salida de la CNN como características de entrada para el modelo de aprendizaje automático, mientras que en otros casos, se pueden combinar las salidas de ambos modelos en una sola salida final. Esto depende en gran medida de la naturaleza de los datos y de los objetivos del proyecto.
Combinar una red neuronal convolucional con otro modelo de aprendizaje automático puede resultar en una mejora significativa en la capacidad de comprensión y análisis de los datos. Esta estrategia se está utilizando cada vez más en diferentes aplicaciones de inteligencia artificial y promete abrir nuevas oportunidades en el campo del aprendizaje automático.
Cuál es el papel de la transferencia de aprendizaje en las redes neuronales convolucionales

La transferencia de aprendizaje es una técnica clave en el funcionamiento de las redes neuronales convolucionales (CNN). En lugar de entrenar una red CNN desde cero, la transferencia de aprendizaje permite aprovechar los conocimientos y patrones aprendidos de tareas previas para mejorar el rendimiento en una nueva tarea.
La idea principal de la transferencia de aprendizaje es que las primeras capas de una red CNN, llamadas capas convolucionales, aprenden características generales como bordes, texturas y formas básicas. Estas características son útiles en muchas tareas de visión por computadora, por lo que pueden ser reutilizadas en diferentes dominios.
Para utilizar la transferencia de aprendizaje, se pueden tomar una o varias de las primeras capas de una red pre-entrenada y combinarlas con nuevas capas para adaptarse a una tarea específica. Este enfoque permite aprovechar el conocimiento previo de las características generales y acelerar el proceso de entrenamiento.
Además, la transferencia de aprendizaje ayuda a evitar el sobreajuste, ya que la red pre-entrenada ha aprendido de una amplia variedad de datos y está generalizada en su representación de características. Esto es especialmente beneficioso cuando se cuenta con un conjunto de datos limitado para la tarea específica.
Ejemplos de aplicaciones de transferencia de aprendizaje en redes neuronales convolucionales
- Clasificación de imágenes: La transferencia de aprendizaje se ha utilizado con éxito en tareas de clasificación de imágenes, como reconocimiento de objetos, detección de rostros y reconocimiento de emociones.
- Segmentación semántica: La transferencia de aprendizaje permite mejorar la precisión en la segmentación semántica de imágenes, donde el objetivo es asignar cada píxel a una clase específica.
- Transferencia de estilo: Se puede utilizar la transferencia de aprendizaje para transferir el estilo de una imagen a otra, creando efectos artísticos.
- Generación de texto: La transferencia de aprendizaje también se ha aplicado en la generación de texto, como la traducción automática y la generación de subtítulos.
La transferencia de aprendizaje es un componente esencial en el funcionamiento de las redes neuronales convolucionales. Permite aprovechar el conocimiento previo de características generales aprendidas en tareas anteriores. Esto acelera el proceso de entrenamiento, evita el sobreajuste y mejora el rendimiento en una amplia gama de aplicaciones de visión por computadora.
Existen retos éticos o de privacidad asociados al uso de redes neuronales convolucionales
El uso de redes neuronales convolucionales (CNN) en aplicaciones de aprendizaje automático plantea retos éticos y de privacidad que deben ser abordados de manera responsable. Estas redes son capaces de aprender y reconocer patrones complejos en grandes conjuntos de datos, lo que las convierte en herramientas poderosas para diversas industrias. Sin embargo, su capacidad para procesar información sensible y personal implica la necesidad de establecer mecanismos de protección y regulación adecuados.
Uno de los principales retos éticos asociados al uso de las CNN es la justicia algorítmica. Estos modelos pueden verse influenciados por sesgos presentes en los datos de entrenamiento, lo que puede llevar a decisiones injustas o discriminatorias. Por ejemplo, en el ámbito de la contratación laboral, un modelo de CNN podría aprender a favorecer a ciertos grupos demográficos sobre otros, perpetuando así desigualdades existentes.
Además, la privacidad de los datos también es un desafío importante. Las redes neuronales convolucionales requieren grandes conjuntos de datos para entrenarse de manera efectiva. Esto implica que las empresas y organizaciones que utilizan estas redes deben gestionar de manera cuidadosa la recopilación, almacenamiento y protección de la información personal de los individuos.
Para abordar estos retos éticos y de privacidad, es necesario establecer marcos regulatorios sólidos que promuevan la transparencia y la rendición de cuentas. Esto implica garantizar el acceso a los algoritmos utilizados, así como a los datos de entrenamiento, para permitir una evaluación adecuada de su imparcialidad. Además, se deben implementar medidas de protección de datos robustas, como el cifrado y el anonimato, para preservar la privacidad de los individuos involucrados.
El uso de redes neuronales convolucionales plantea desafíos éticos y de privacidad que deben ser abordados de manera rigurosa. Es responsabilidad de la sociedad y de las organizaciones que utilizan estas tecnologías garantizar que su implementación se realice de manera justa y respetuosa con los derechos de las personas. Solo así podremos aprovechar todo el potencial de estas redes en beneficio de la sociedad.
Qué se puede hacer para mejorar el rendimiento y la precisión de una red neuronal convolucional
Existen varias estrategias que se pueden implementar para mejorar el rendimiento y la precisión de una red neuronal convolucional (CNN por sus siglas en inglés). A continuación, se detallarán algunas de las principales técnicas utilizadas en el ámbito del aprendizaje automático.
Aumento de datos
Una forma efectiva de mejorar el rendimiento de una CNN es aumentar la cantidad de datos disponibles para el entrenamiento. Esto se puede lograr aplicando diferentes técnicas de aumento de datos, como rotación, traslación, cambio de escala y cambio de color. Al generar diferentes versiones de las imágenes originales, se enriquece el conjunto de datos de entrenamiento y se ayuda a la red a generalizar mejor.
Uso de arquitecturas más profundas
Otra estrategia para mejorar el rendimiento de una CNN es utilizar arquitecturas más profundas. A medida que aumenta la profundidad de la red, esta puede aprender características más complejas y abstractas de las imágenes. Sin embargo, es importante encontrar un equilibrio, ya que el uso de arquitecturas muy profundas puede llevar a problemas de sobreajuste.
Técnicas de regularización
Las técnicas de regularización son fundamentales para mejorar la generalización de una CNN. Una de las técnicas más comunes es la regularización L2, que agrega un término de penalización al costo de la red para evitar que los pesos tomen valores excesivamente altos. Otra técnica es la utilización de Dropout, que consiste en desactivar aleatoriamente una fracción de las neuronas durante el entrenamiento, lo que reduce la dependencia entre ellas.
Optimización de hiperparámetros
Los hiperparámetros son los parámetros de la red que no se aprenden durante el entrenamiento, como la tasa de aprendizaje, el tamaño del lote y el número de épocas. La optimización de estos hiperparámetros es esencial para lograr un rendimiento óptimo de una CNN. Esto se puede lograr utilizando técnicas de búsqueda en cuadrícula o utilizando algoritmos de optimización como el descenso de gradiente estocástico.
Transferencia de aprendizaje
La transferencia de aprendizaje es una técnica que consiste en utilizar una red neuronal previamente entrenada en un problema similar y adaptarla a un nuevo problema. Al aprovechar el conocimiento previo de la red, se puede acelerar enormemente el entrenamiento y mejorar el rendimiento de la CNN en el nuevo problema. Esto es especialmente útil en escenarios en los que el conjunto de datos de entrenamiento es limitado.
Utilización de hardware especializado
Para mejorar aún más el rendimiento de una CNN, se puede utilizar hardware especializado, como las unidades de procesamiento gráfico (GPU) o los circuitos integrados de aplicaciones específicas (ASIC). Estos dispositivos están diseñados específicamente para acelerar el procesamiento de redes neuronales y permiten entrenar y evaluar modelos de forma mucho más rápida que utilizando una CPU convencional.
Existen diferentes estrategias y técnicas que se pueden implementar para mejorar el rendimiento y la precisión de una red neuronal convolucional. La combinación de aumento de datos, uso de arquitecturas más profundas, técnicas de regularización, optimización de hiperparámetros, transferencia de aprendizaje y utilización de hardware especializado puede llevar a resultados sobresalientes en problemas de aprendizaje automático.
Preguntas frecuentes (FAQ)
1. ¿Qué es una red neuronal convolucional (CNN)?
Una red neuronal convolucional es un tipo de modelo de aprendizaje automático utilizado principalmente en el procesamiento de imágenes y reconocimiento visual.
2. ¿Cómo funciona una red neuronal convolucional?
Una CNN se compone de múltiples capas de neuronas artificiales, también conocidas como filtros, que se aplican a la imagen de entrada para extraer características importantes. Estas características se utilizan para realizar la clasificación o detección de objetos.
3. ¿Cuál es la ventaja de utilizar una red neuronal convolucional en el procesamiento de imágenes?
Una CNN es capaz de aprender características relevantes de forma automática a partir de los datos de entrenamiento, lo que la convierte en una poderosa herramienta para el procesamiento de imágenes. Además, su arquitectura permite el procesamiento en paralelo, lo que acelera el tiempo de entrenamiento y predicción.
4. ¿Cuál es el proceso de entrenamiento de una red neuronal convolucional?
El entrenamiento de una CNN implica alimentar al modelo con un conjunto de imágenes etiquetadas y ajustar los pesos de las neuronas para minimizar la función de pérdida. Esto se hace mediante el uso de algoritmos de optimización como el descenso de gradiente estocástico.
5. ¿En qué aplicaciones se utiliza una red neuronal convolucional?
Las redes neuronales convolucionales se utilizan en una amplia gama de aplicaciones, incluyendo reconocimiento facial, clasificación de imágenes, detección de objetos, segmentación semántica, entre otras.