
Red Neuronal Transformer: Funcionamiento y Aplicaciones
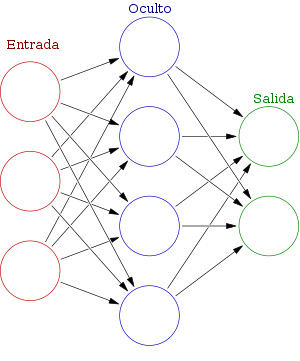
Las redes neuronales transformer son un tipo de modelo de aprendizaje automático que ha ganado mucha popularidad en los últimos años debido a su capacidad para procesar y generar texto de manera efectiva. Estas redes se basan en una arquitectura novedosa que utiliza mecanismos de atención para capturar las relaciones entre las palabras en un texto. A diferencia de las redes neuronales recurrentes tradicionales, las redes neuronales transformer son capaces de procesar todo el texto de manera simultánea, lo que las hace mucho más eficientes en términos de velocidad de entrenamiento y capacidad de capturar relaciones a largo plazo.
Exploraremos en detalle el funcionamiento de las redes neuronales transformer y su arquitectura característica. Veremos cómo estas redes utilizan mecanismos de atención para procesar el texto y capturar las relaciones entre las palabras. También discutiremos algunas de las aplicaciones más comunes de las redes neuronales transformer, como la traducción automática y la generación de texto. Además, hablaremos de los desafíos y limitaciones asociados con estas redes y las investigaciones actuales en el campo para mejorar su rendimiento y eficiencia. Este artículo servirá como una introducción completa a las redes neuronales transformer y su relevancia en el campo del procesamiento de lenguaje natural.
- Cómo funciona una red neuronal transformer y qué la hace diferente de otros modelos de redes neuronales
- Cuáles son las aplicaciones más comunes de las redes neuronales transformer en la actualidad
- Qué ventajas ofrece una red neuronal transformer en comparación con otros modelos de redes neuronales
- Cuáles son los principales desafíos y limitaciones de las redes neuronales transformer en su aplicación práctica
- Existen herramientas o frameworks específicos para entrenar y utilizar redes neuronales transformer
- Cuál es el papel de la atención en el funcionamiento de una red neuronal transformer
- Cómo se pueden mejorar y optimizar las redes neuronales transformer para obtener mejores resultados en diferentes tareas
- Qué tipos de datos son más adecuados para entrenar una red neuronal transformer? ¿Existen requisitos específicos en términos de tamaño o formato de los datos
- Cuál es la influencia del tamaño del modelo en el rendimiento y la eficiencia de una red neuronal transformer
- Cuáles son las últimas investigaciones y avances en el campo de las redes neuronales transformer? ¿Cómo se espera que evolucione esta tecnología en el futuro
-
Preguntas frecuentes (FAQ)
- 1. ¿En qué consiste una red neuronal transformer?
- 2. ¿Cuál es la diferencia entre una red neuronal transformer y una red neuronal convolucional?
- 3. ¿Cuál es el funcionamiento de una red neuronal transformer?
- 4. ¿Para qué se utiliza una red neuronal transformer?
- 5. ¿Cuáles son algunas aplicaciones prácticas de las redes neuronales transformer?
Cómo funciona una red neuronal transformer y qué la hace diferente de otros modelos de redes neuronales
Una red neuronal transformer es un modelo de aprendizaje automático que ha revolucionado el campo de la inteligencia artificial. A diferencia de otros modelos de redes neuronales, como las redes neuronales recurrentes (RNN) o las redes neuronales convolucionales (CNN), las redes neuronales transformer se basan en la atención para procesar secuencias de datos.
La atención es una técnica que permite a la red neural enfocarse en partes específicas de una secuencia. Esto es especialmente útil en tareas de procesamiento de lenguaje natural, donde se requiere comprender el contexto y la relación entre las palabras.
En una red neuronal transformer, cada palabra de una secuencia se representa como un vector de alta dimensionalidad. Estos vectores, también conocidos como embeddings, se utilizan para calcular la atención entre las diferentes palabras de la secuencia. El resultado de esta atención se utiliza para actualizar los embeddings y obtener una representación contextualizada de las palabras.
Una de las principales ventajas de las redes neuronales transformer es su capacidad para procesar secuencias completas de una sola vez, en lugar de depender de una propagación secuencial como en las RNN. Esto las hace mucho más eficientes en términos de tiempo de entrenamiento y predicción.
Otra característica destacada de las redes neuronales transformer es su capacidad para capturar relaciones de largo alcance. A través de la atención, estas redes son capaces de relacionar palabras que se encuentran lejos unas de otras en una secuencia, lo que les permite comprender mejor la estructura y el contexto de los datos.
Una red neuronal transformer es un modelo de aprendizaje automático basado en la atención que permite procesar secuencias completas y capturar relaciones de largo alcance. Esta arquitectura ha demostrado obtener resultados destacados en tareas de procesamiento de lenguaje natural, como la traducción automática o la generación de texto.
Cuáles son las aplicaciones más comunes de las redes neuronales transformer en la actualidad
Las redes neuronales transformer se han convertido en una herramienta poderosa en el campo del procesamiento del lenguaje natural. Su capacidad para modelar relaciones a largo plazo y su capacidad de atención han llevado a numerosas aplicaciones exitosas en diversas áreas.
Una de las aplicaciones más comunes de las redes neuronales transformer es la traducción automática. Gracias a su capacidad de atención, estas redes pueden identificar los elementos clave en una oración y generar traducciones precisas y coherentes. Esto ha revolucionado la forma en que las personas se comunican en diferentes idiomas, eliminando las barreras lingüísticas.
Otra aplicación importante es la generación de texto. Las redes neuronales transformer pueden generar texto coherente y de calidad, lo que ha impulsado el desarrollo de chatbots y asistentes virtuales más humanos. Estos sistemas pueden responder preguntas, realizar tareas y brindar información útil a los usuarios.
Las redes neuronales transformer también se utilizan en el análisis de sentimientos. Gracias a su capacidad de atención, estas redes pueden identificar las emociones expresadas en un texto y determinar si es positivo, negativo o neutral. Esto es especialmente útil en el análisis de opiniones en redes sociales y en el monitoreo de la satisfacción del cliente.
Otro campo en el que las redes neuronales transformer han demostrado su eficacia es en la generación de resúmenes automáticos. Estas redes pueden leer y comprender grandes cantidades de texto y luego resumirlo de manera concisa. Esto ha sido útil en la industria del periodismo y en la extracción de información relevante de documentos extensos.
Finalmente, las redes neuronales transformer también se utilizan en la generación de código. Estas redes pueden aprender a escribir código fuente a partir de ejemplos y generar soluciones programáticas. Esto ha facilitado el desarrollo de software y ha mejorado la eficiencia en la programación.
Qué ventajas ofrece una red neuronal transformer en comparación con otros modelos de redes neuronales
La red neuronal transformer es un modelo innovador que ha revolucionado el campo de la inteligencia artificial. A diferencia de otros modelos de redes neuronales, como las redes convolucionales o las recurrentes, la red neuronal transformer se basa en un mecanismo de atención que le permite procesar secuencias completas de datos de manera más eficiente.
Una de las principales ventajas de la red neuronal transformer es su capacidad para capturar relaciones de largo alcance entre las distintas partes de una secuencia. Mientras que otros modelos de redes neuronales dependen principalmente de la proximidad en el tiempo o en el espacio, la red neuronal transformer puede identificar y modelar relaciones complejas a lo largo de toda una secuencia.
Otra ventaja importante de la red neuronal transformer es su capacidad para manejar secuencias de longitud variable. A diferencia de otros modelos de redes neuronales, que requieren un tamaño fijo de entrada, la red neuronal transformer es capaz de procesar secuencias de cualquier longitud. Esto la hace especialmente útil en aplicaciones donde los datos son inherentemente variables, como el procesamiento de lenguaje natural.
Además, la red neuronal transformer tiene una arquitectura paralelizable, lo que significa que puede procesar múltiples partes de una secuencia al mismo tiempo. Esto permite acelerar significativamente el entrenamiento y la inferencia de la red, lo que la hace especialmente adecuada para aplicaciones en tiempo real.
La red neuronal transformer ofrece varias ventajas significativas en comparación con otros modelos de redes neuronales. Su capacidad para capturar relaciones de largo alcance, manejar secuencias de longitud variable y su arquitectura paralelizable la convierten en una opción prometedora para una amplia gama de aplicaciones en el campo de la inteligencia artificial.
Cuáles son los principales desafíos y limitaciones de las redes neuronales transformer en su aplicación práctica
Las redes neuronales transformer han revolucionado el campo del procesamiento del lenguaje natural y han demostrado un rendimiento excepcional en diversas tareas, como la traducción automática y la generación de texto. Sin embargo, a pesar de sus numerosos éxitos, existen desafíos y limitaciones en su aplicación práctica que vale la pena explorar.
Uno de los principales desafíos de las redes neuronales transformer es su alto consumo de recursos computacionales. Debido a la complejidad de su arquitectura y a la gran cantidad de parámetros que deben ser entrenados, estas redes requieren una gran capacidad de procesamiento y memoria, lo que limita su uso en dispositivos con recursos limitados.
Otro desafío importante es la necesidad de grandes cantidades de datos etiquetados para entrenar adecuadamente una red neuronal transformer. Estas redes necesitan una gran cantidad de ejemplos de entrada y salida para aprender patrones y reglas lingüísticas, lo que puede ser costoso y complicado de obtener en ciertos dominios o idiomas poco comunes.
Además, las redes neuronales transformer son propensas a errores de generalización y sobreajuste. Esto significa que pueden tener dificultades para adaptarse a nuevos datos o contextos que no se encuentren en el conjunto de entrenamiento, lo que limita su capacidad de aplicarse a tareas del mundo real que requieren flexibilidad y adaptabilidad.
En cuanto a las limitaciones, las redes neuronales transformer tienden a tener dificultades para manejar correctamente la ambigüedad y la incertidumbre del lenguaje natural. Aunque pueden generar resultados precisos en muchas ocasiones, también pueden cometer errores o producir salidas confusas cuando se enfrentan a oraciones o palabras ambiguas que requieren un mayor contexto o conocimiento específico.
Otra limitación importante es la falta de interpretabilidad de las redes neuronales transformer. A pesar de su efectividad en la generación de texto, estas redes son cajas negras en términos de cómo procesan y representan el lenguaje. Esto dificulta la comprensión de cómo y por qué se toman ciertas decisiones, lo que puede ser problemático en aplicaciones donde la transparencia y la explicabilidad son fundamentales.
A pesar de estos desafíos y limitaciones, las redes neuronales transformer siguen siendo una herramienta poderosa en el procesamiento del lenguaje natural. Con avances continuos en la investigación y el desarrollo de nuevas arquitecturas y técnicas de entrenamiento, es probable que estas limitaciones se superen en el futuro, lo que permitirá una mayor aplicabilidad y adopción de estas redes en una amplia gama de escenarios prácticos.
Existen herramientas o frameworks específicos para entrenar y utilizar redes neuronales transformer
El entrenamiento y la utilización de redes neuronales transformer requieren el uso de herramientas o frameworks específicos que facilitan la implementación y optimización de este tipo de modelos. Algunas de las herramientas más populares incluyen TensorFlow, PyTorch y Hugging Face's Transformers. Estas herramientas proporcionan una serie de funciones y API que permiten cargar y preprocesar datos, definir la arquitectura del modelo, entrenar la red neuronal, realizar inferencias y evaluar su rendimiento.
TensorFlow es una de las herramientas más utilizadas para entrenar redes neuronales transformer. Proporciona una amplia variedad de capas y módulos que permiten construir modelos complejos de manera eficiente. Además, TensorFlow ofrece un conjunto de herramientas de visualización y depuración que facilitan el análisis y la mejora de los modelos.
Por otro lado, PyTorch se ha convertido en una opción popular entre los investigadores y desarrolladores debido a su flexibilidad y facilidad de uso. PyTorch permite definir y entrenar modelos de manera intuitiva, utilizando una sintaxis similar a Python. Además, PyTorch ofrece una gran cantidad de recursos y tutoriales que ayudan a los usuarios a comprender y mejorar sus modelos de redes neuronales transformer.
Otra herramienta importante en el campo de las redes neuronales transformer es Hugging Face's Transformers. Esta biblioteca proporciona una interfaz sencilla para cargar y utilizar una amplia variedad de modelos de lenguaje preentrenados, como BERT, GPT y RoBERTa. Hugging Face's Transformers también ofrece una gran cantidad de utilidades y funciones de procesamiento de lenguaje natural que facilitan el desarrollo de aplicaciones basadas en redes neuronales transformer.
El entrenamiento y la utilización de redes neuronales transformer requieren el uso de herramientas o frameworks específicos que simplifican la implementación y optimización de estos modelos. TensorFlow, PyTorch y Hugging Face's Transformers son algunas de las herramientas más populares en este campo, ofreciendo una serie de funciones y API que permiten cargar datos, definir la arquitectura del modelo, entrenar la red neuronal, realizar inferencias y evaluar su rendimiento.
Cuál es el papel de la atención en el funcionamiento de una red neuronal transformer
La atención es un componente clave en el funcionamiento de una red neuronal transformer. Permite a la red enfocarse en partes específicas de la entrada y asignar importancia a esas partes. La atención se logra mediante la asignación de pesos a diferentes partes de la entrada. Estos pesos determinan qué partes de la entrada son más relevantes para la tarea que se está realizando.
La atención en una red neuronal transformer se puede ver como una serie de capas de atención. Cada capa toma como entrada la salida de la capa anterior y la utiliza para calcular los pesos de atención. Estos pesos se utilizan luego para calcular una representación ponderada de la entrada. Esta representación ponderada es entonces utilizada por la red para realizar la tarea que se le ha asignado.
La atención en una red neuronal transformer es única en comparación con otros enfoques de atención. En lugar de utilizar una atención basada en localidad, la atención en una red neuronal transformer es global. Esto significa que la red puede enfocarse en cualquier parte de la entrada, independientemente de su posición en la secuencia. Esto es especialmente útil en tareas en las que es importante considerar contextos de largo alcance.
Aplicaciones de la atención en una red neuronal transformer
La atención en una red neuronal transformer tiene diversas aplicaciones. Una de las aplicaciones más conocidas es en la traducción automática. La atención permite que la red se centre en partes específicas de la oración de origen y las utilice para generar la traducción correspondiente. Esto mejora significativamente la calidad de las traducciones generadas.
Otra aplicación importante de la atención en una red neuronal transformer es en la generación de texto. La red puede utilizar la atención para enfocarse en palabras clave relevantes en un texto de entrada y utilizarlas para generar texto coherente y relevante en la salida. Esto es especialmente útil en tareas como la generación de subtítulos automáticos o la generación de resúmenes de texto.
Además de la traducción automática y la generación de texto, la atención en una red neuronal transformer también se utiliza en tareas como el reconocimiento de voz, el procesamiento de lenguaje natural y la generación de imágenes. En todos estos casos, la atención permite mejorar el rendimiento de la red al permitirle enfocarse en las características más relevantes de la entrada.
Cómo se pueden mejorar y optimizar las redes neuronales transformer para obtener mejores resultados en diferentes tareas
Las redes neuronales transformer han revolucionado el campo del procesamiento del lenguaje natural. Su arquitectura única y su capacidad para capturar correlaciones a largo plazo han permitido avances significativos en tareas como la traducción automática y la generación de texto.
Sin embargo, a pesar de su eficacia, todavía existe margen para mejorar y optimizar estas redes. Una forma de lograrlo es mediante la incorporación de mecanismos de atención más avanzados. La atención es uno de los componentes clave de las redes neuronales transformer y determina cómo se deben distribuir los recursos de procesamiento a lo largo de la secuencia de entrada o salida.
Los mecanismos de atención existentes, como la atención uniforme, tienen limitaciones en términos de capacidad para capturar relaciones complejas. Una posible mejora sería utilizar una atención más focalizada, como la atención ponderada, que asigna diferentes pesos a diferentes partes de la secuencia según su relevancia. Esto permitiría una mayor flexibilidad y adaptación a diferentes tareas y contextos.
Otra forma de mejorar las redes neuronales transformer es mediante la incorporación de mecanismos de atención multi-head. Esta técnica consiste en utilizar múltiples cabezas de atención en lugar de una sola, lo cual permite capturar relaciones multi-granulares y diferentes aspectos del texto de manera simultánea. Cada cabeza de atención se especializa en diferentes aspectos de la secuencia, lo que mejora la capacidad de la red para capturar información relevante.
Aplicaciones de las redes neuronales transformer en diversas áreas
Las redes neuronales transformer tienen aplicaciones en una amplia variedad de áreas, más allá del procesamiento del lenguaje natural. Una de sus aplicaciones más destacadas es en la generación de texto, donde se utilizan para crear contenido de manera automática, como en la redacción de noticias o la producción de guiones.
Otra área donde las redes neuronales transformer han sido aplicadas con éxito es en el reconocimiento de voz. Estas redes son capaces de capturar las características más relevantes de la secuencia de entrada de audio y convertirlas en texto, lo que permite una transcripción precisa y eficiente.
Además, las redes neuronales transformer se han utilizado también en el campo de la visión por computadora. En tareas como el reconocimiento de objetos o el etiquetado automático de imágenes, estas redes pueden capturar y modelar las relaciones espaciales y temporales entre los diferentes elementos de una imagen, lo que mejora la precisión y la capacidad de generalización.
Las redes neuronales transformer son una herramienta poderosa en el campo del procesamiento del lenguaje natural y tienen aplicaciones en diversas áreas. Con las mejoras y optimizaciones adecuadas, estas redes pueden seguir avanzando y ofreciendo resultados cada vez más precisos y eficientes.
Qué tipos de datos son más adecuados para entrenar una red neuronal transformer? ¿Existen requisitos específicos en términos de tamaño o formato de los datos
Los modelos de Red Neuronal Transformer son conocidos por su capacidad para procesar grandes cantidades de datos y obtener resultados precisos en tareas de procesamiento del lenguaje natural. Sin embargo, no todos los tipos de datos son igualmente adecuados para entrenar una red neuronal transformer.
En general, los datos que se utilizan para entrenar este tipo de modelo deben ser textuales. Esto significa que deben estar representados por secuencias de palabras o caracteres. Además, es importante que los datos sean lo más diversos y representativos posible, ya que esto permite al modelo aprender patrones y características más generales.
Requisitos de tamaño y formato
En cuanto al tamaño de los datos, no hay un límite específico. Sin embargo, es recomendable contar con una cantidad suficientemente grande de datos para obtener mejores resultados. En general, se sugiere contar con al menos varios miles o millones de ejemplos para el entrenamiento de una red neuronal transformer.
En cuanto al formato de los datos, estos deben estar estructurados de manera coherente y consistente. Por ejemplo, si los datos están representados por frases o documentos, es importante que sigan un formato estándar para facilitar su procesamiento.
Además, es importante preprocesar los datos antes de utilizarlos para entrenar una red neuronal transformer. Esto implica realizar tareas como la tokenización, donde se dividen las palabras o caracteres en unidades más pequeñas, como tokens, y la normalización de texto, donde se convierten todas las letras a minúsculas y se eliminan caracteres especiales.
Los datos más adecuados para entrenar una red neuronal transformer son aquellos que son textuales y están representados por secuencias de palabras o caracteres. Además, es recomendable contar con una cantidad suficientemente grande de datos y seguir un formato coherente y consistente. Asimismo, se deben realizar tareas de preprocesamiento para garantizar un mejor rendimiento del modelo.
Cuál es la influencia del tamaño del modelo en el rendimiento y la eficiencia de una red neuronal transformer
El tamaño del modelo en una red neuronal transformer tiene una gran influencia en su rendimiento y eficiencia. Cuanto más grande es el tamaño del modelo, mayor es la capacidad de la red para capturar relaciones y patrones complejos en los datos de entrada. Esto se debe a que un modelo más grande tiene más parámetros para aprender y ajustar los pesos de las conexiones entre las neuronas.
Sin embargo, un tamaño de modelo más grande también puede afectar negativamente el rendimiento y la eficiencia de la red. Esto se debe a que un modelo más grande requiere más memoria y tiempo de computación para entrenar y ejecutar. Además, un tamaño de modelo más grande puede aumentar la posibilidad de sobreajuste, donde la red se ajusta demasiado a los datos de entrenamiento y no generaliza bien a nuevos datos.
Por lo tanto, encontrar el equilibrio adecuado entre el tamaño del modelo y el rendimiento/eficiencia es crucial en una red neuronal transformer. Esto implica realizar ajustes y experimentos con diferentes tamaños de modelos para encontrar el punto óptimo donde se logre un buen rendimiento sin comprometer demasiado la eficiencia.
Cuáles son las últimas investigaciones y avances en el campo de las redes neuronales transformer? ¿Cómo se espera que evolucione esta tecnología en el futuro

Las redes neuronales transformer han revolucionado el campo del procesamiento del lenguaje natural y la traducción automática. Su innovador mecanismo de atención ha demostrado ser altamente eficiente en la captura de relaciones semánticas y contextuales en secuencias de texto largas.
En los últimos años, se han realizado numerosas investigaciones y avances en el desarrollo de redes neuronales transformer. Uno de los logros más destacados ha sido el diseño de modelos cada vez más profundos y complejos que superan el rendimiento de las técnicas tradicionales.
Además, se han explorado variantes de las redes neuronales transformer para abordar desafíos específicos, como la generación de texto coherente, la resolución de la ambigüedad lingüística y la adaptación a diferentes dominios. Estas variantes incluyen el BERT (Bidirectional Encoder Representations from Transformers), GPT (Generative Pre-trained Transformer) y LNet (etreme MultiLabel Pretraining for Neural Networks).
En cuanto a las aplicaciones, las redes neuronales transformer han sido ampliamente utilizadas en tareas de traducción automática, resumen de texto, generación de lenguaje natural y respuesta a preguntas. También han demostrado ser efectivas en el análisis de sentimientos, reconocimiento de voz y generación de música y arte.
En el futuro, se espera que las redes neuronales transformer continúen evolucionando y mejorando su capacidad de comprensión y generación de lenguaje natural. Se espera que se desarrollen modelos aún más profundos y complejos, capaces de capturar matices y sutilezas en el texto.
Asimismo, se prevé que se investigue más en la interpretación de las decisiones tomadas por las redes neuronales transformer, de modo que se puedan comprender mejor los procesos internos y evitar posibles sesgos o errores.
Las redes neuronales transformer son una tecnología prometedora con un amplio rango de aplicaciones en el procesamiento del lenguaje natural. Su capacidad para capturar relaciones contextuales y semánticas ha dado lugar a mejoras significativas en diversas tareas. Con el continuo desarrollo e investigación, estas redes continuarán siendo una herramienta fundamental en el avance de la inteligencia artificial.
Preguntas frecuentes (FAQ)
1. ¿En qué consiste una red neuronal transformer?
Una red neuronal transformer es un modelo de aprendizaje automático basado en la atención que se utiliza principalmente en el procesamiento del lenguaje natural.
2. ¿Cuál es la diferencia entre una red neuronal transformer y una red neuronal convolucional?
A diferencia de las redes neuronales convolucionales, las redes neuronales transformer no requieren capas convolucionales ni de pooling, ya que se basan en el mecanismo de atención para capturar las relaciones entre las palabras en un texto.
3. ¿Cuál es el funcionamiento de una red neuronal transformer?
Una red neuronal transformer se compone de múltiples capas de atención que permiten al modelo enfocarse en las partes relevantes de la entrada y capturar las relaciones entre las palabras. Estas capas de atención se combinan con capas de feed-forward para generar representaciones contextuales de las palabras.
4. ¿Para qué se utiliza una red neuronal transformer?
Las redes neuronales transformer se utilizan en una amplia variedad de tareas de procesamiento del lenguaje natural, como la traducción automática, la generación de texto, el resumen de documentos y el reconocimiento de voz.
5. ¿Cuáles son algunas aplicaciones prácticas de las redes neuronales transformer?
Algunas aplicaciones prácticas de las redes neuronales transformer incluyen asistentes virtuales, sistemas de recomendación, análisis de sentimientos, detección de spam y clasificación de documentos.